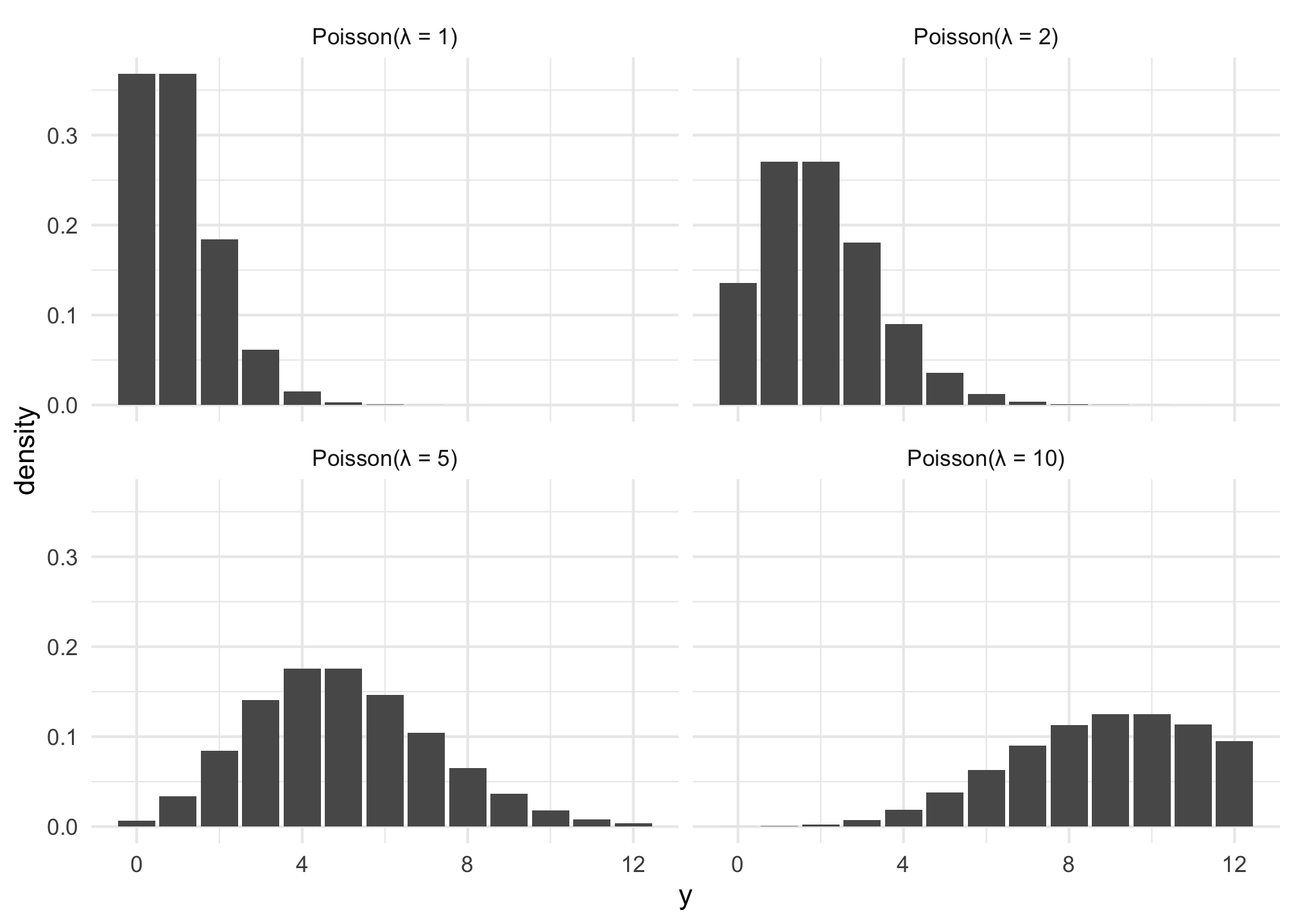
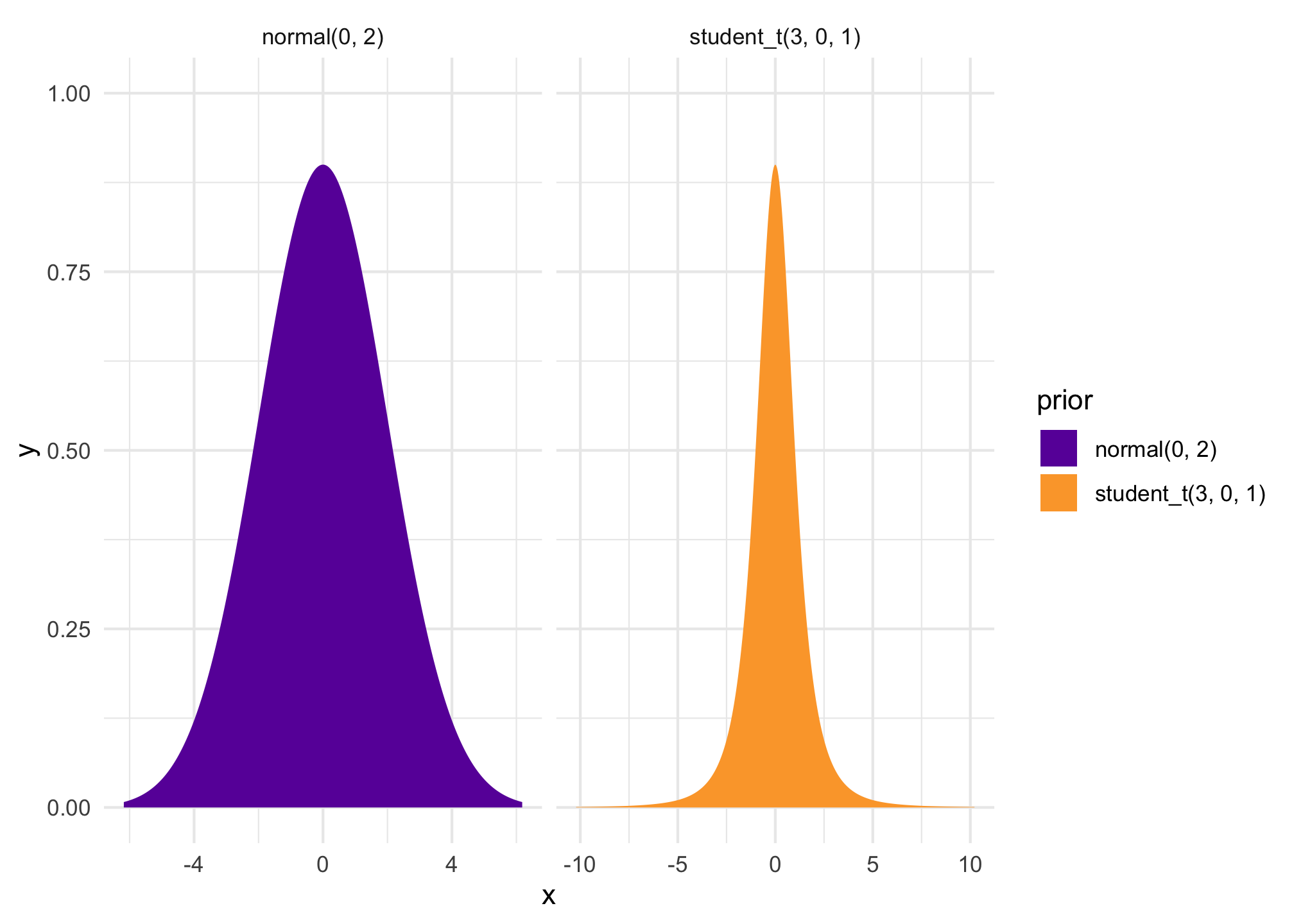
The Poisson distribution represents counts that are produced based on a rate; variable values must be integers.
The distribution uses only one parameter \(\lambda\) (lambda), which controls the rate and represents both the mean and the variance/standard deviation.
The negative binomial distribution also represents counts based on a rate, but it allows the variance to be different from the mean and takes two parameters: \(\mu\) (mu) for the mean and \(r\) for the dispersion.
For instance, let’s say you’re sitting at the front door of a coffee shop (in pre-COVID days) and you count how many people are in each arriving group. You’ll see something like this:
1 person
1 person
2 people
1 person
3 people
2 people
1 person
Lots of groups of one, some groups of two, fewer groups of three, and so on. That’s a Poisson process: a bunch of independent random events that combine into grouped events.
Lots of real life things follow this pattern: household size, the number of cars in traffic, the number of phone calls received by an office, arrival times in a line, and even the outbreak of wars.
In general, as the rate of events \(\lambda\) increases…
We can use regression to model the \(\lambda\) of a Poisson-distributed outcome. In Poisson models, the \(\lambda\) rate must be positive. But if you model \(\lambda\) with a regression model like
Example: Modeling the count of LGBTQ+ anti-discrimination laws
We want to model the number of LGBTQ+ anti-discrimination laws in states based on how urban a state is and its historical partisan voting patterns. Here’s the general relationship. A regular straight OLS line doesn’t fit the data well, but because the outcome is a count, and because the general relationship is curvy, Poisson regression will work.
Code
ggplot(equality, aes(x = percent_urban, y = laws)) +geom_point(aes(fill = historical), pch =21, size =4, color ="white") +geom_smooth(aes(color ="Poisson regression"), se =FALSE, method ="glm", method.args =list(family ="poisson") ) +geom_smooth(aes(color ="OLS regression"), se =FALSE, method ="lm") +scale_fill_manual(values =c(clr_dem, clr_gop, clr_ind)) +scale_color_manual(values =c("#3D9970", "#FF851B")) +labs(x ="Percent urban", y ="Count of laws", color =NULL, fill ="Party" ) +theme(legend.position ="bottom")
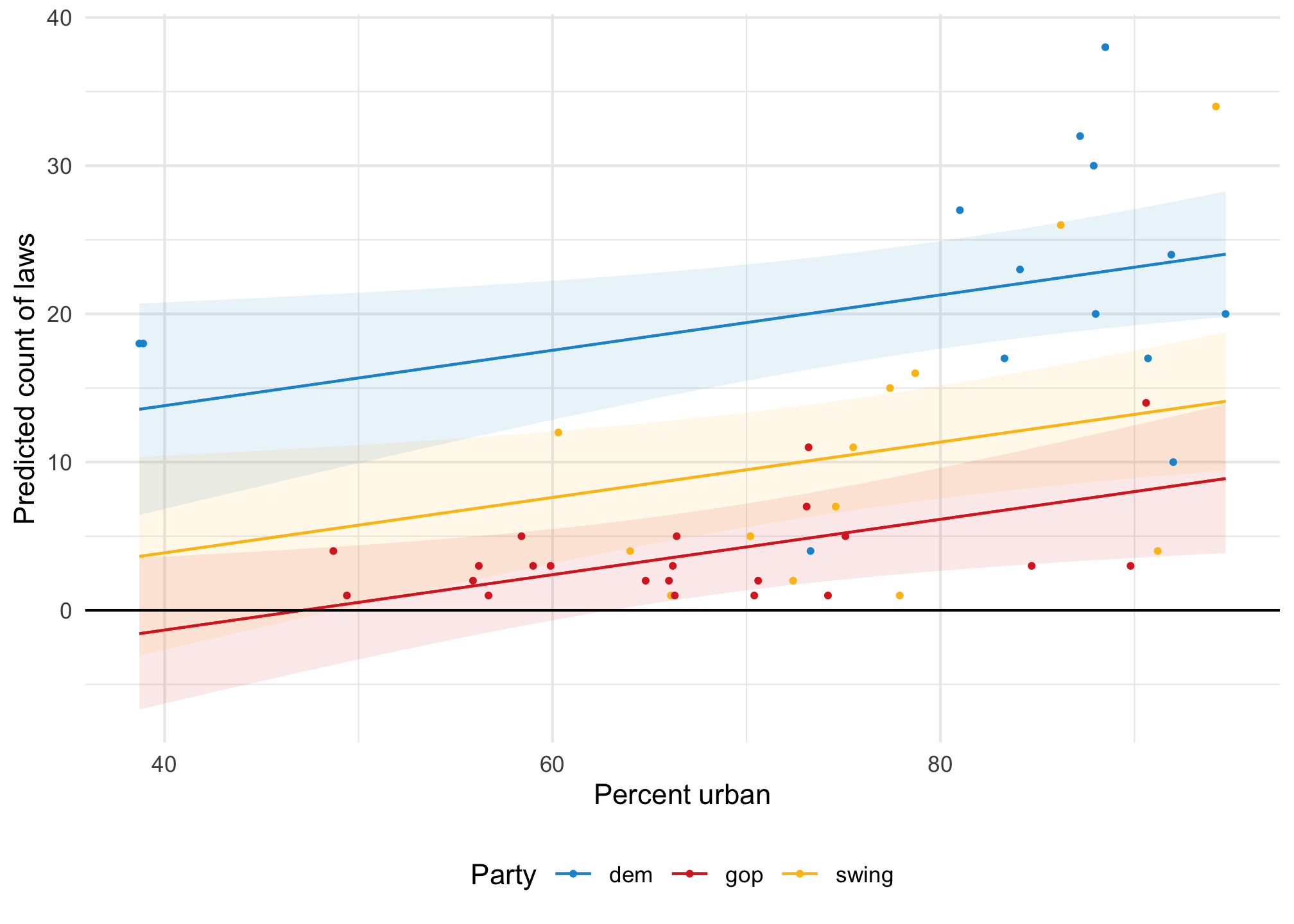
If we model this with regular OLS, we’ll get predictions of negative laws:
Code
model_ols <-lm(laws ~ percent_urban + historical, data = equality)plot_predictions(model_ols, condition =c("percent_urban", "historical")) +geom_hline(yintercept =0) +geom_point(data = equality, aes(x = percent_urban, y = laws, color = historical),size =0.75 ) +scale_color_manual(values =c(clr_dem, clr_gop, clr_ind)) +scale_fill_manual(values =c(clr_dem, clr_gop, clr_ind), guide ="none") +labs(x ="Percent urban", y ="Predicted count of laws", color ="Party" ) +theme(legend.position ="bottom")
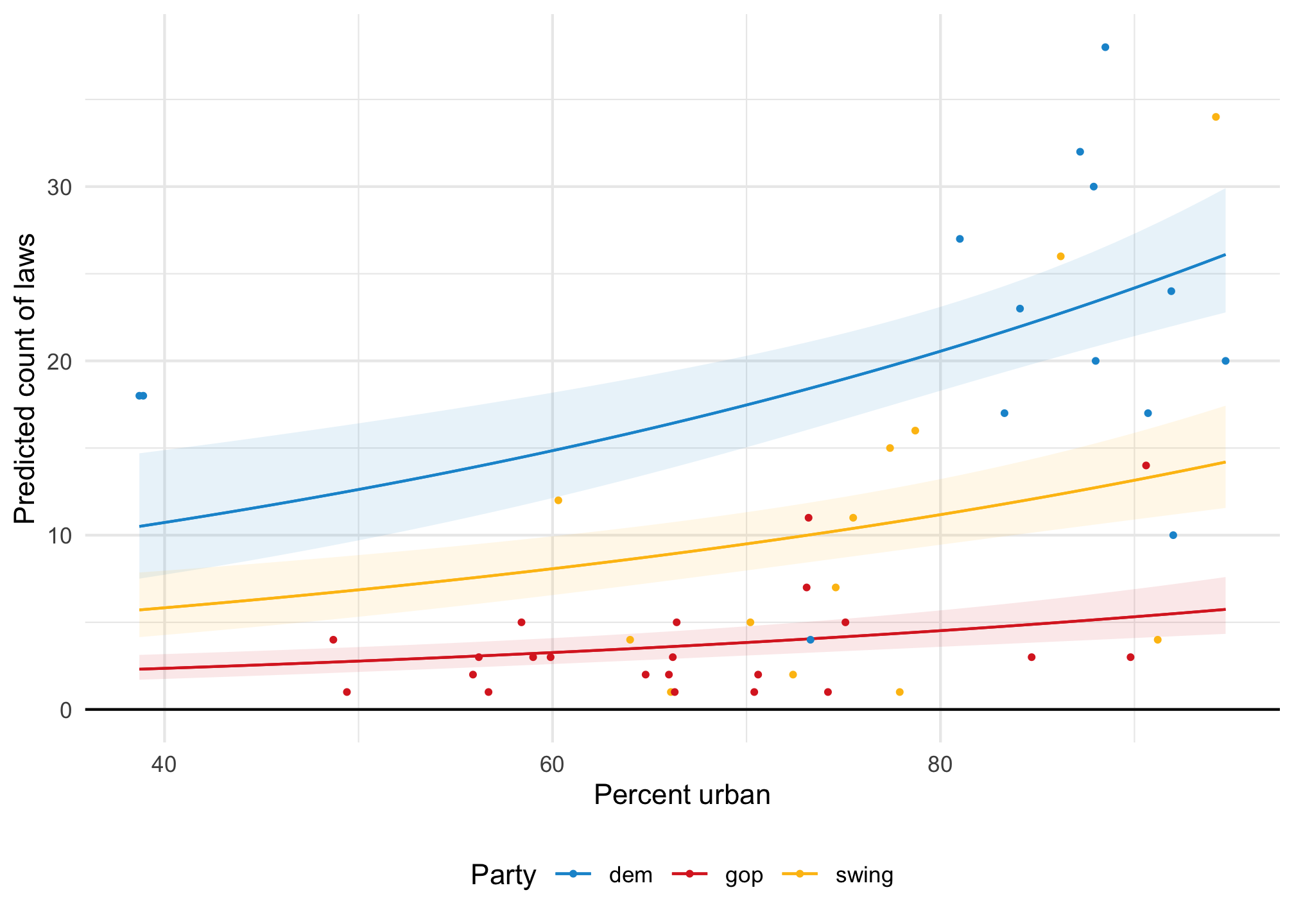
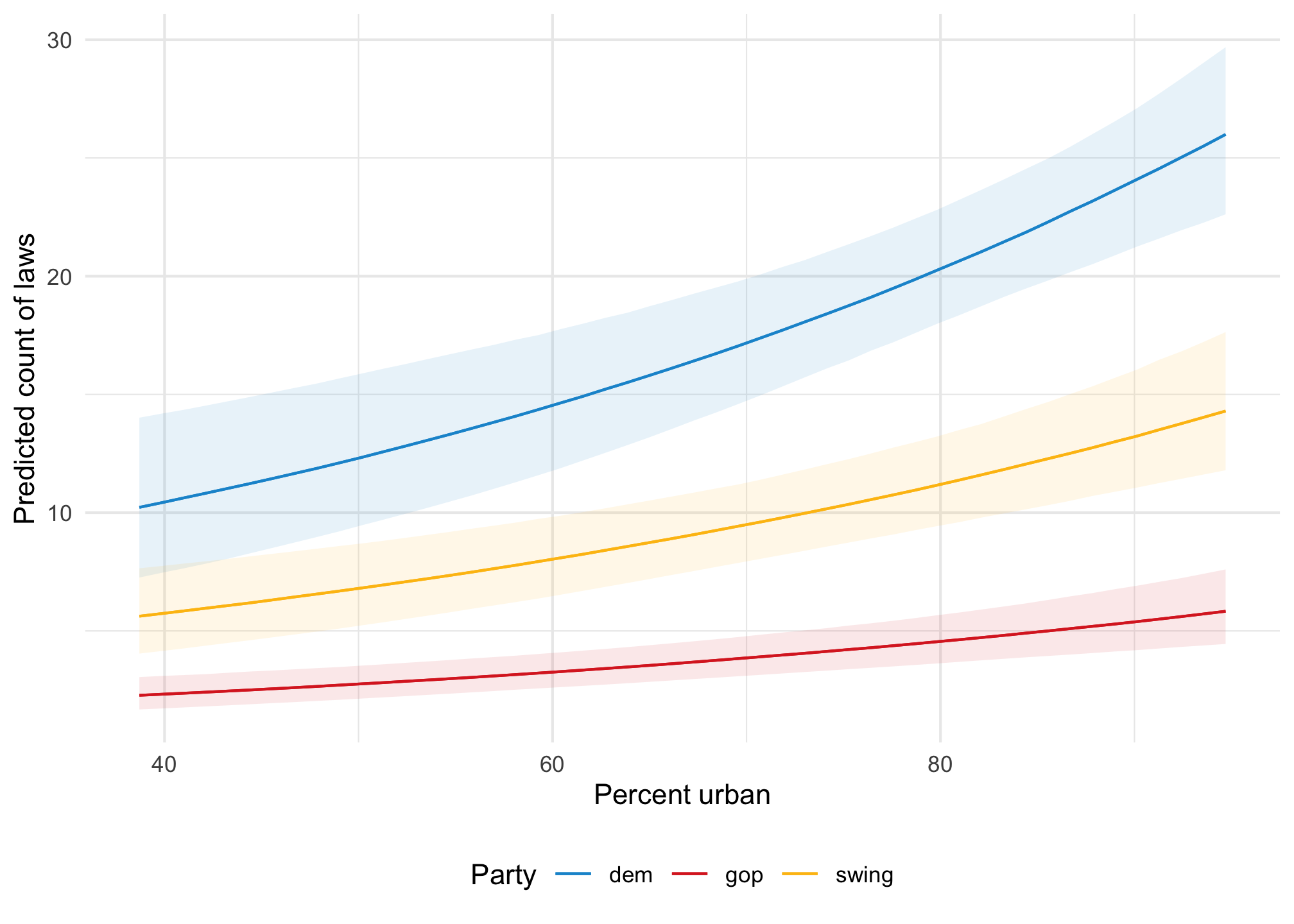
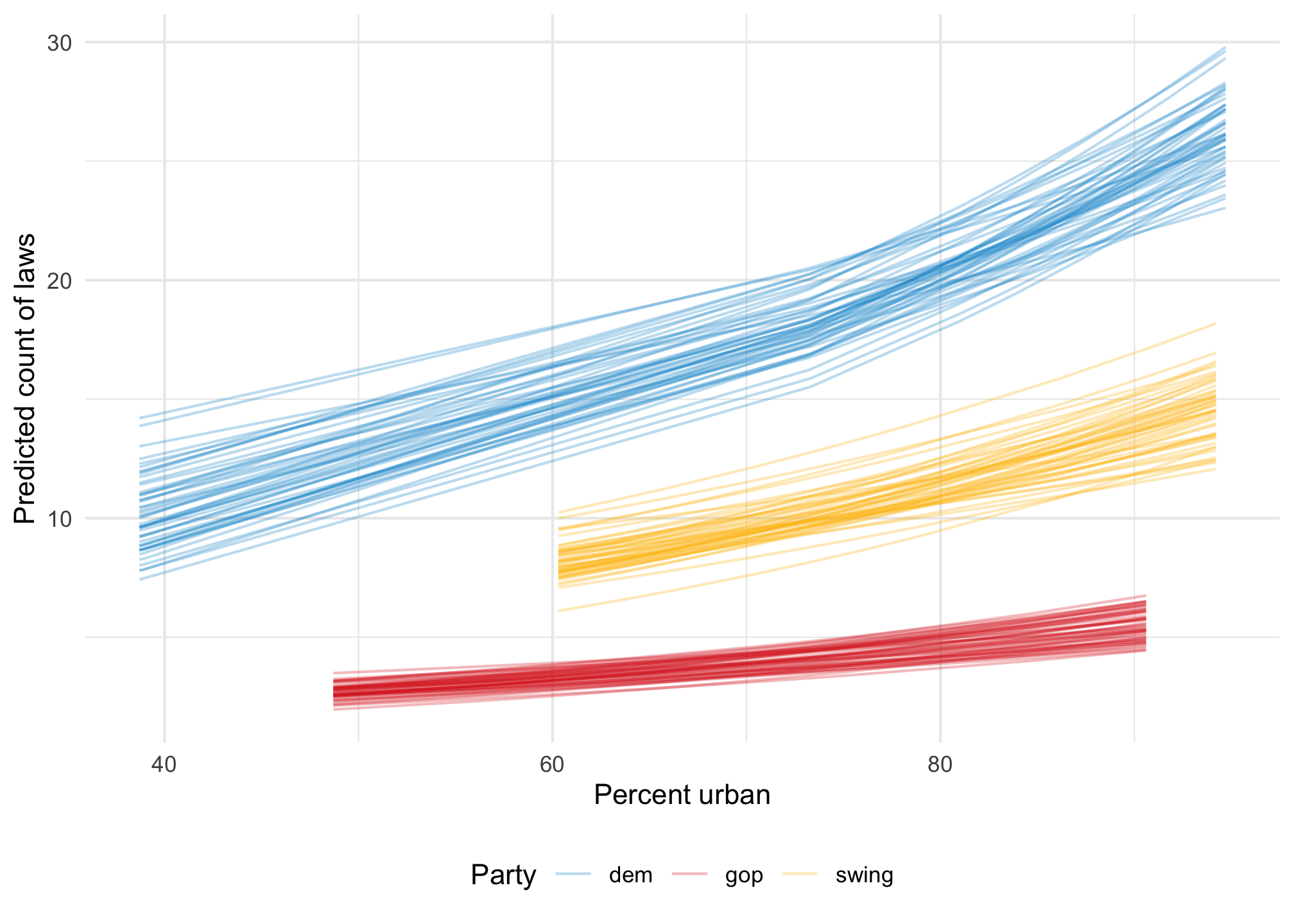
If we model it using Poisson, all the predictions are positive and the predicted lines are curvy and better fit the data:
Code
model_poisson <-glm( laws ~ percent_urban + historical, data = equality,family =poisson(link ="log"))plot_predictions(model_poisson, condition =c("percent_urban", "historical")) +geom_hline(yintercept =0) +geom_point(data = equality, aes(x = percent_urban, y = laws, color = historical),size =0.75 ) +scale_color_manual(values =c(clr_dem, clr_gop, clr_ind)) +scale_fill_manual(values =c(clr_dem, clr_gop, clr_ind), guide ="none") +labs(x ="Percent urban", y ="Predicted count of laws", color ="Party" ) +theme(legend.position ="bottom")
Interpreting coefficients
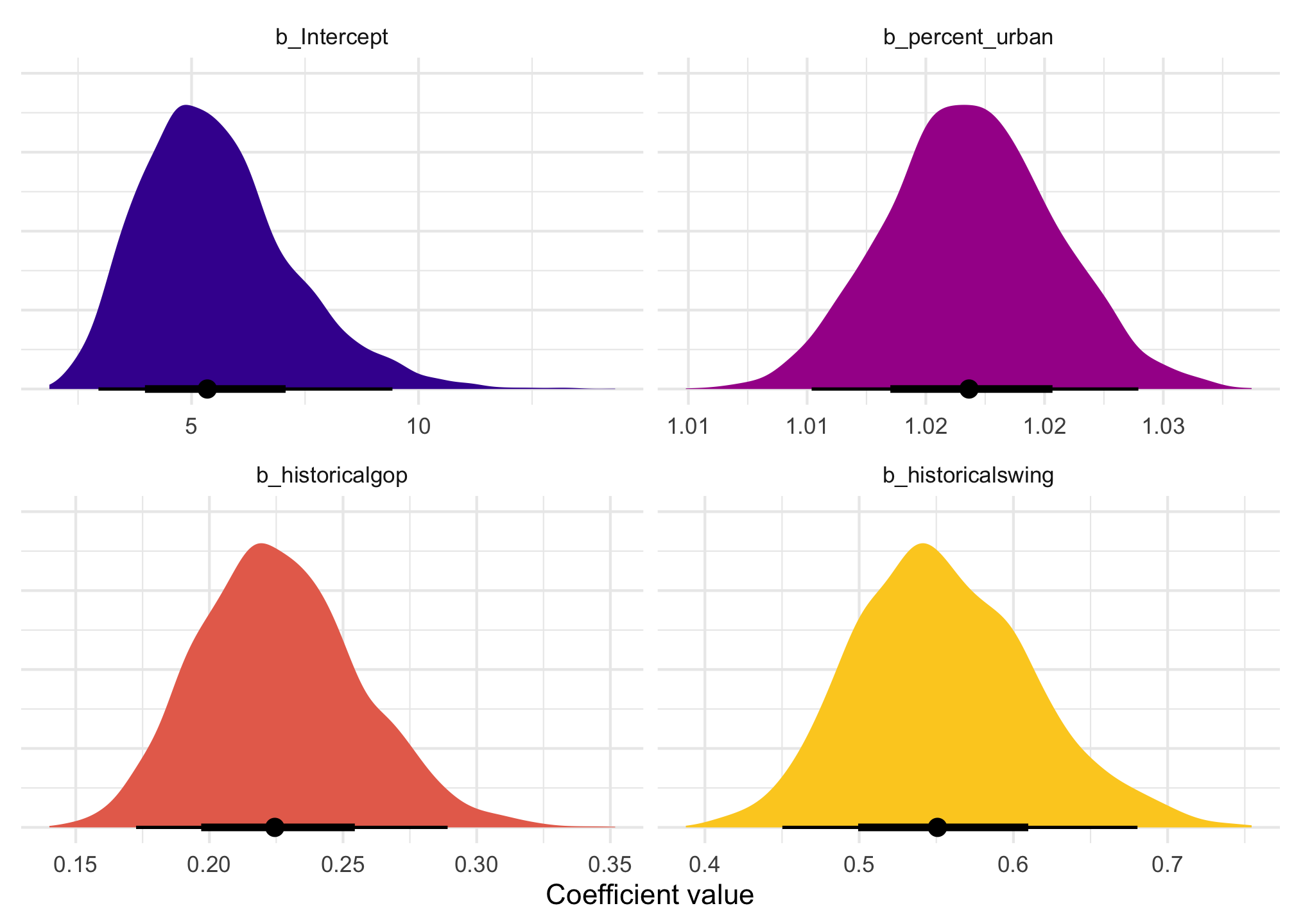
The coefficients in the model are on a logged scale, which make them a little weird to work with. Here’s a basic frequentist model, with coefficients logged and exponentiated:
For the intercept \(\beta_0\), this is the intercept on the logged scale when percent urban is 0 in historically Democratic states (since it’s the omitted base case). We can backtransform this to the response/count scale by exponentiating it: \(e^{1.7225} = 5.599\). That means that in a historically Democratic non-urban state, we’d expect to see 5.6 anti-discrimination laws.
But the most un-urban Democratic states are Maine and Vermont, each at 38% urban, so the intercept isn’t super important here.
For the percent urban \(\beta_1\) coefficient, this is the slope of the line on the log scale. We can expect the logged number of laws in states to increase by 0.0163 for every additional percentage point of urban-ness. To make that more interpretable we can exponentiate it (\(e^{0.0163} = 1.0164\)), which means that a 1 percentage point increase in urban-ness is associated with 1.0164 times more anti-discrimination laws (or 1.64%)
For the party/historical\(\beta_2\) and \(\beta_3\) coefficients, these are the shifts in the logged Democratic intercept (again because it’s the omitted base case). We’d thus expect the logged number of laws in GOP states to be 1.5 lower on average. That makes no sense when logged, but if we exponentiate it (\(e^{-1.5145} = 0.2199\)), we find that GOP states should have 22% as many anti-discrimination laws as a Democratic state (or only 22% of what a typical Democratic state would have).
Even when exponentiated, these coefficients are a litte weird because they’re not on the scale of the outcome. They don’t represent changes in counts, but percent changes (e.g. increasing urbanness is associated with 1.64% more laws, not some count of laws).
To make life even easier, we can calculate marginal effects instead and get count-level changes in the outcome at specific values of urbanness or across the whole range of the fitted line.
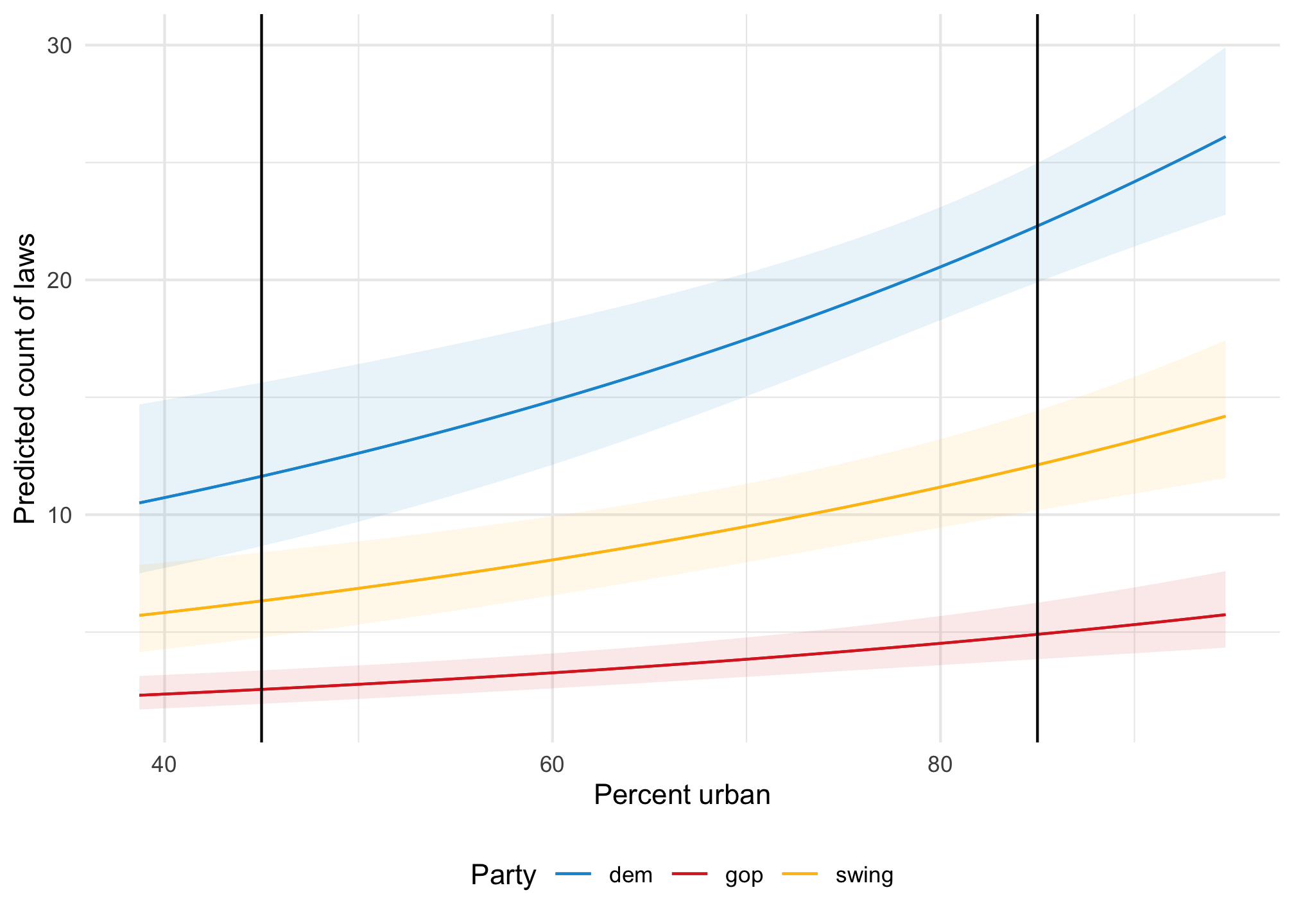
Remember the fitted lines here—the effect or slope of urbanness changes depending on two things:
The political party: the line is higher and steeper for democratic states
The level of urbanness: the line is shallower in less urban states; steeper in urban states
Code
plot_predictions(model_poisson, condition =c("percent_urban", "historical")) +geom_vline(xintercept =c(45, 85)) +scale_color_manual(values =c(clr_dem, clr_gop, clr_ind)) +scale_fill_manual(values =c(clr_dem, clr_gop, clr_ind), guide ="none") +labs(x ="Percent urban", y ="Predicted count of laws", color ="Party" ) +theme(legend.position ="bottom")
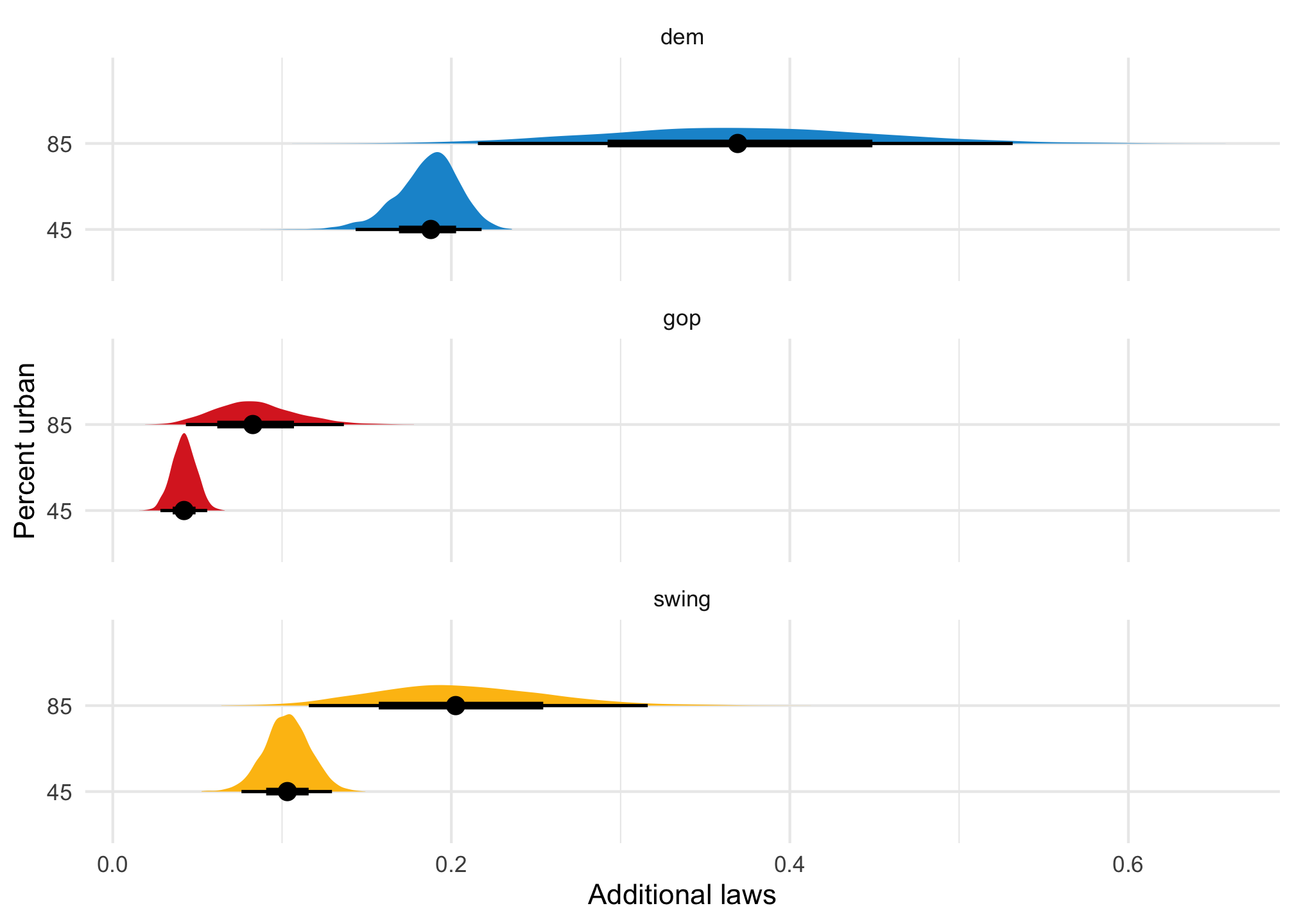
The effect of urbanness on the count of laws is different when a state is less urban (45%) vs. more urban (85%). We can calculate count-level slopes at each of those points:
In Democratic states, a 1 percentage point increase in urbanness is associated with 0.189 additional laws in rural (45%) states and 0.363 additional laws in urban (85%) states; in Republican states, a 1 percentage point increase in urbanness is associated with 0.04 additional laws in rural (45%) states and 0.08 ladditional laws in urban (85%) states.
Instead of disaggregating everything by party and choosing arbitrary values of urbanness, we can also find the overall average slope of the line. Across all states and parties and different levels of urbanness, a 1 percentage point increase in urbanness is associated with 0.17 additional laws, on average.